주간책톡(부산 도서관) 크롤링 -2 XPath, CSS_SELECTOR
2023. 4. 24. 20:17ㆍ프로젝트/주간책톡
<tr>
<td>
<font>value</font>
<font>value2</font>
<font>value3</font>
</td>
</tr>이런 형태의 웹이 있다고 하자. class 나, id 가 다 부모노드에 있어서 <font> 의 특정 값을 특정할수 class 나 id 로 특정 지을수 없을때. xpath 로 해결한다.


단순 CSS_SELECTOR 로 class 가 없는 td 태그 내의 font 태그의 요소를 찾으면 저 조건을 만족하는 모든 값이 다 크롤링 된다.
author = driver.find_element(By.XPATH, '//tr/td/font[1]')
저자만 뽑히긴 했는데 사족이 달려있다. 원래 구조에서는 보지 못했던 것들.
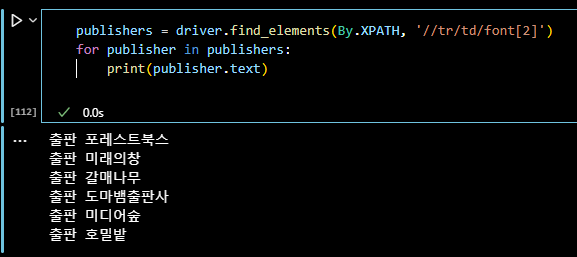
[2]로 출판만 잘 나오는것을 확인.
-> //tr/td/font 로 시작하는 다른 형제노드가 있다고 판단.

확인하니 책 소개 문구인데. 리스트에 [저자,문구,저자2,문구2,...] 이런식이기에 써도 인덱싱해서 사용해도 된다고 판단.
하지만 공부하는 목적에서 이 부분을 제거하고 순수한 저자만 크롤링 하도록 연습.
개인적으로 실력이 미진해서 그런가 힘들었다.
하지만 저자,출판,출간,소개 문구 4개를 크롤링 하는것보다
저자만 크롤링 할수 있으면 컴퓨팅 리소스를 25%만 사용해도 되는 것이다.

td:not([class]) > font:not(:has(> img))선택자로 img 태그를 가진 font 태그는 걸러 내었다.(소개 문구 font 태그에 img 태그를 자식으로 가짐)
결론
헛고생 한거 같은데 공부는 되었다!
728x90
'프로젝트 > 주간책톡' 카테고리의 다른 글
| 주간책톡(부산 도서관) 크롤링 -6 카카오톡 메세지 크롤링, pygetwindow, pyautogui (2) | 2023.05.01 |
|---|---|
| 주간책톡(부산 도서관) 크롤링 -5 페이지를 순회하며 크롤링 (0) | 2023.04.27 |
| 주간책톡(부산 도서관) 크롤링 -4 표의 형태를 어떻게 api 로 전송하지?(tabulate, matplotlib) (0) | 2023.04.26 |
| 주간책톡(부산 도서관) 크롤링 -3 책 정보를 dataframe화 (pandas) (0) | 2023.04.25 |
| 주간책톡(부산 도서관) 크롤링 -1 CSS 선택자 (0) | 2023.04.24 |